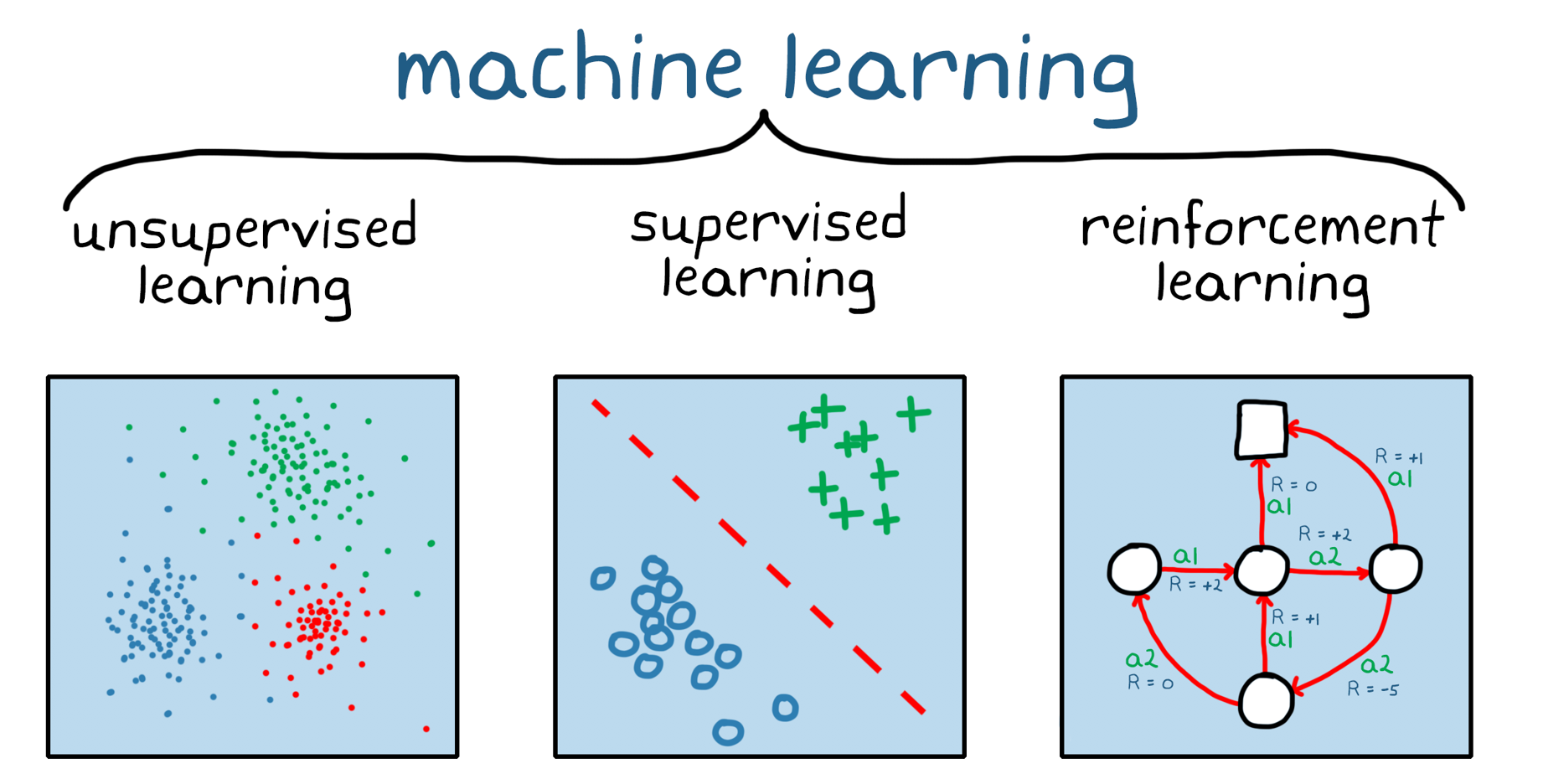
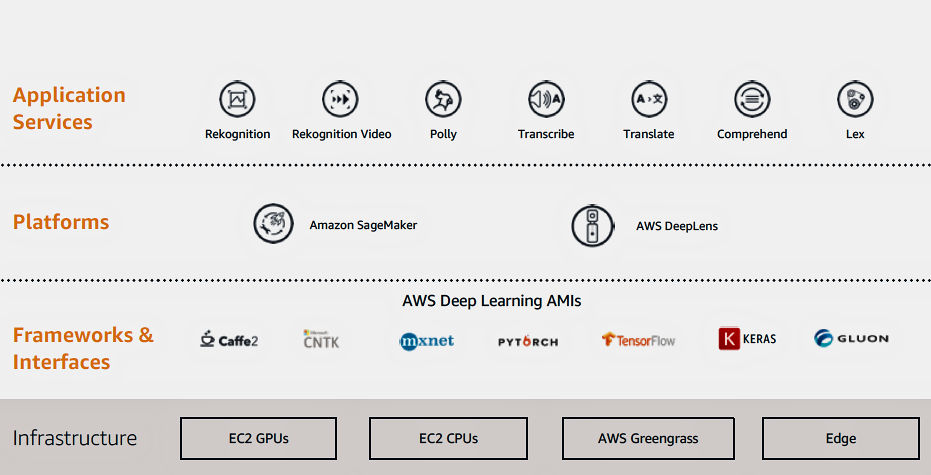
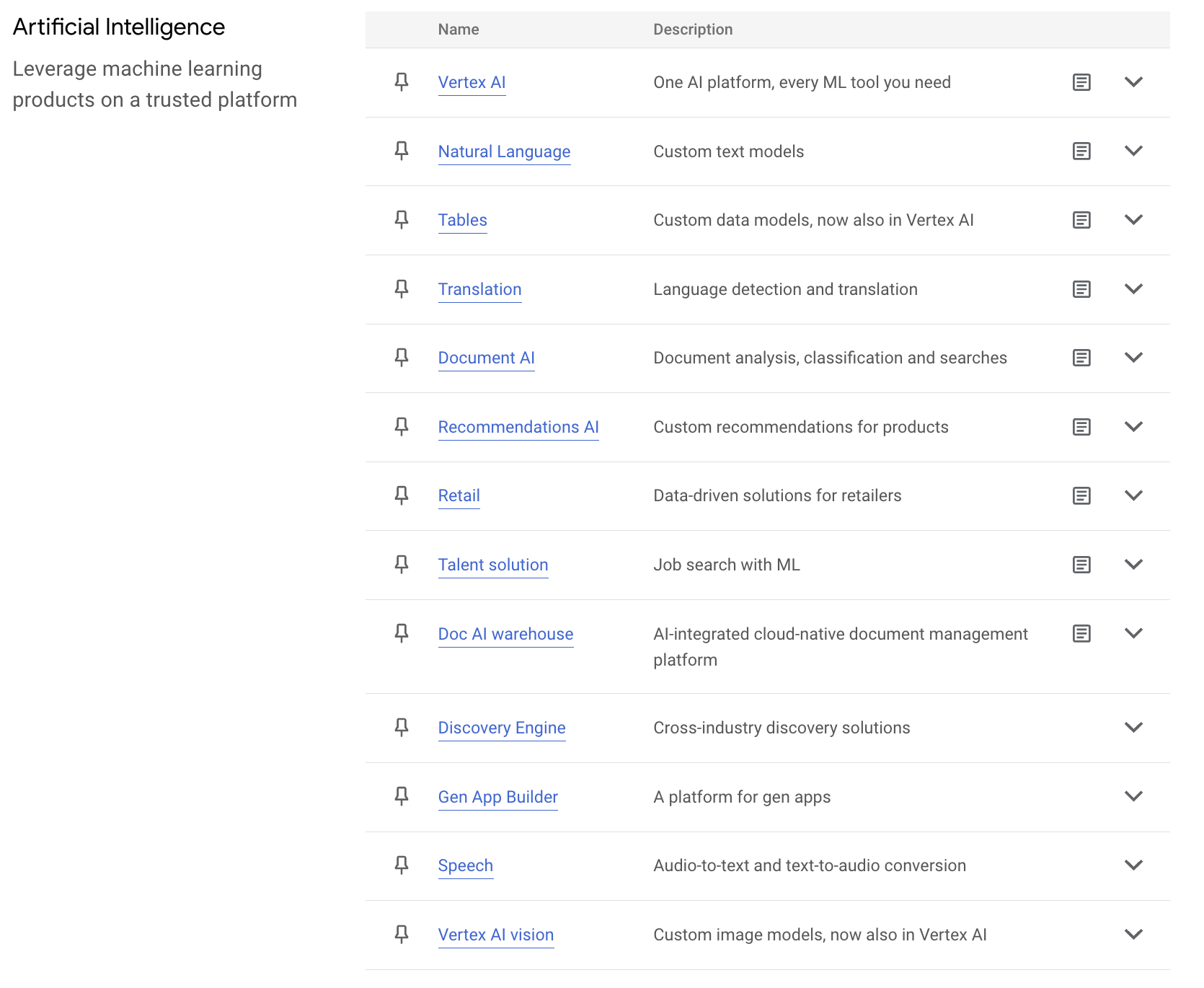
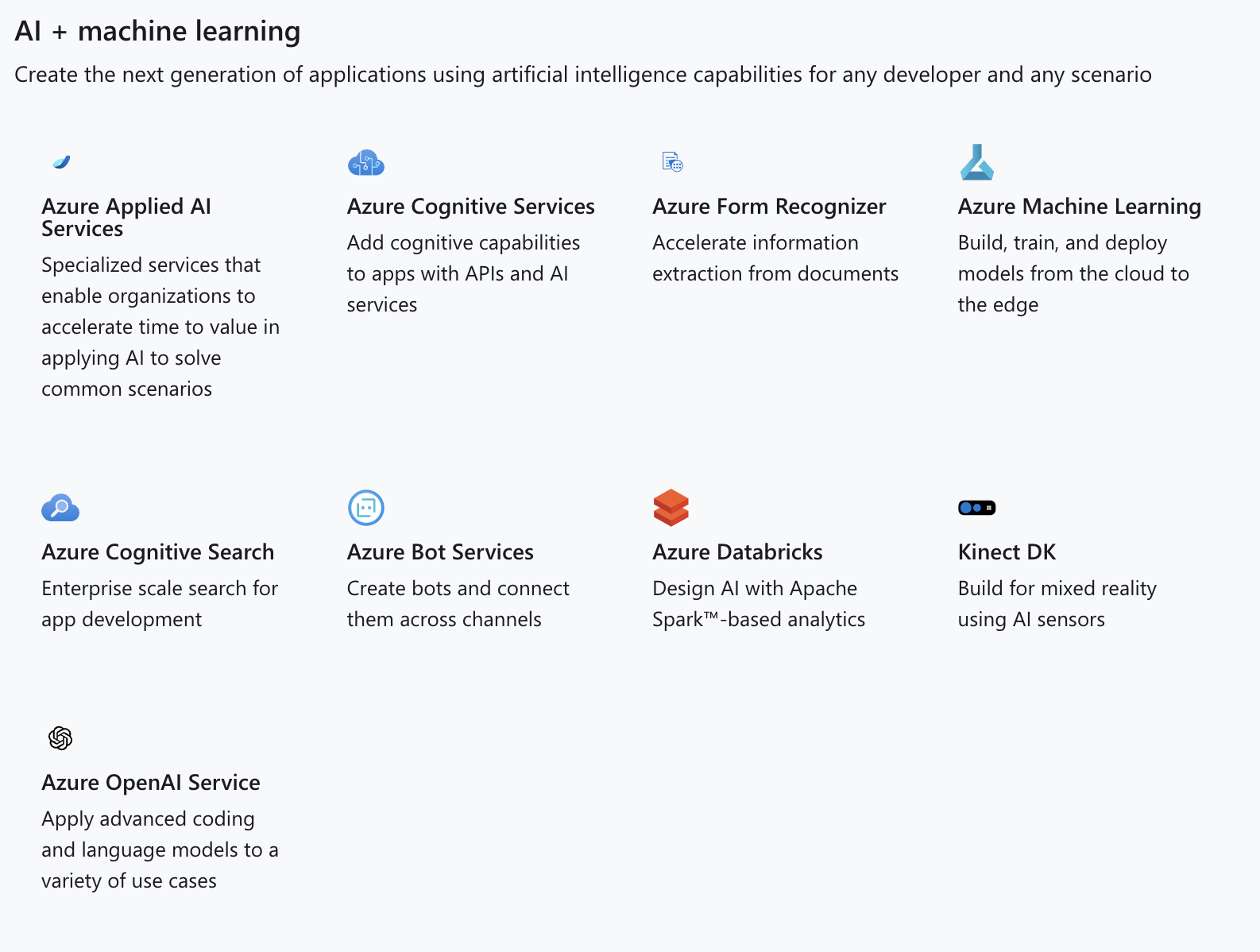
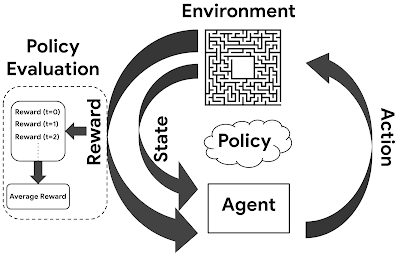
有關強化學習,是個用獎勵值、而無需人手標記的學習方法,用例子例如學習玩 Mario 遊戲(双寶兄弟 / 超級馬利歐兄弟)。我們大多都是用以下這個模型來解釋。而強化學習的演算法,是可以簡約分類:Off-policy or On-policy、Policy-base or Value-based、Model-based or Model-free。這進入較深奧的架構和方法論討論,暫先略去不提。這方面若有興趣,找一般的強化學習 (Reinforcement Learning) 的教科書看都會包括有這些分類方法。
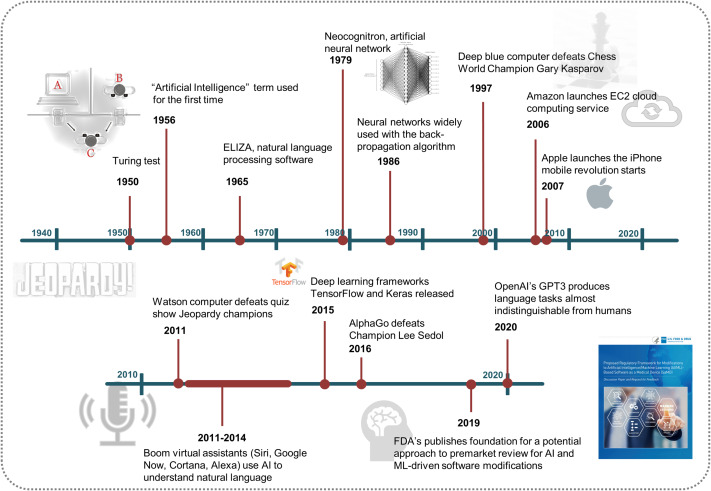
智能安全的幾個定律
在智能安全題目上,有幾個著名定律:
Morphy’s Law 墨菲定律:任何會有可能錯的事情,都會發生錯誤。(Anything that can go wrong will go wrong.)
Asimov’s Laws 艾西莫夫定律 / Three Laws of Robotics 機械人三定律 (1942);後來加上了第零法則 (1985):
第零法則:機器人不得傷害整體人類,或坐視整體人類受到傷害;(A robot may not harm humanity, or, by inaction, allow humanity to come to harm.)
第一法則:除非違背第零法則,否則機器人不得傷害人類,或坐視人類受到傷害;(A robot may not injure a human being or, through inaction, allow a human being to come to harm.)
第二法則:機器人必須服從人類命令,除非命令與第零或第一法則發生衝突;(A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.)
第三法則:在不違背第零、第一或第二法則之下,機器人要保護自己。(A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.)