上篇提到智能叛變。這篇討論下智能安全。智能安全的概念可以追縱到 1960,但具體討論都是追溯到大約 2008 – 2011 或之後。
智能安全 (AI Safety) 和智能認同 (AI Alignment),筆者相信應該也是另一個智能的研究。因為只有智能可以防衛另一個智能,這也大概是其中一個主流派別的觀點。主要原因之一,大概是因為人工智能上天然上有著絕對優勢。
有關機器的天然優勢
例如現代電腦晶片前線,2023 年一般都在 3 納米 (3nm) 和 10 GHz(一百億Hz,1GHz為十億)為今年標準。對比電腦,人類腦部運作在 200 Hz 的速度。還要這只是個人電腦或手提電話(例如 Apple Silicon M3 或 Intel 3)的晶片標準。還未計電腦可以複製多部電腦,遵從統一意志。
現時設定
智能的研究在智能安全方面,有點像資安一樣分紅隊 (Red teaming)。對於資安 (Cybersecurity) 來說,紅隊就是白帽 (White Hats);而對於人工智能的紅隊就是負責智能認同 (AI Alignment)。
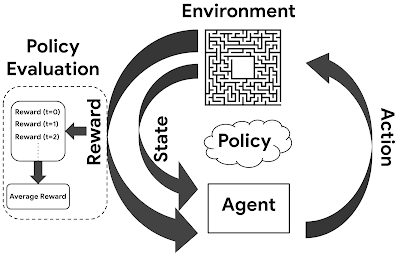
強化學習 (Reinforcement Learning) 模型是以三個模型功能 (Policy-based: Policy, Reward, Environmental),也有 Value-based 的方法;筆者以往在解釋 Google 的 AlphaGo 的演算法時,也在專欄上分享過(2017.06.03, Startupbeats 連結)。例如 GPT4,因為要禁戒它不能回答些敏感字句,它的設計上是有另一個模型限制它的回答。架構上:
- Policy Model:負責管理 Policy 引導智能。
- Reward Model:負責給予 Policy Model 獎勵 (Reward)。獎勵是用來導向強化學習中,人工智能的學習方向。例如制止它給予一些不恰當的回答。
- Environmental Model:負責估計環境或其他持份者會怎樣回應;也可以估計未來的獎勵 (Reward)。
筆者有時會講笑說,這個設計,和90年代庵野秀明的著名動畫《Evangelion 新世紀福音戰士》中,總部由赤木律子博士的母親直子開發的人工智能「三賢人」很像。而剛巧 openAI 的 CTO Mira Murati 也是位(美)女生。(有關個美字請自己找其國藉或相片)
而智能認同的方法,都是在堅固性 / 可靠性、可監控性、能力限制、可核證性、防止智能追求權力,等等這些方面作研究範疇。
智能認同 (AI Alignment) 或智能控制問題 (AI Control Problem) 不是鐵版一塊的。原理有點像經濟政策討論,是有幾個條件之間同時平衡,例如:一方面要讓它發展;但又要在安全範圍內;但若管束太多就會失去活力和發展速度;而又永遠會有其他研究單位在巿場競爭。而智能認同 (AI Alignment) 或智能安全 (AI Safety) 就是在這樣的環境中的一個問題。
有關強化學習,是個用獎勵值、而無需人手標記的學習方法,用例子例如學習玩 Mario 遊戲(双寶兄弟 / 超級馬利歐兄弟)。我們大多都是用以下這個模型來解釋。而強化學習的演算法,是可以簡約分類:Off-policy or On-policy、Policy-base or Value-based、Model-based or Model-free。這進入較深奧的架構和方法論討論,暫先略去不提。這方面若有興趣,找一般的強化學習 (Reinforcement Learning) 的教科書看都會包括有這些分類方法。
智能安全的幾個定律
在智能安全題目上,有幾個著名定律:
- Morphy’s Law 墨菲定律:任何會有可能錯的事情,都會發生錯誤。(Anything that can go wrong will go wrong.)
- Asimov’s Laws 艾西莫夫定律 / Three Laws of Robotics 機械人三定律 (1942);後來加上了第零法則 (1985):
- 第零法則:機器人不得傷害整體人類,或坐視整體人類受到傷害;(A robot may not harm humanity, or, by inaction, allow humanity to come to harm.)
- 第一法則:除非違背第零法則,否則機器人不得傷害人類,或坐視人類受到傷害;(A robot may not injure a human being or, through inaction, allow a human being to come to harm.)
- 第二法則:機器人必須服從人類命令,除非命令與第零或第一法則發生衝突;(A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.)
- 第三法則:在不違背第零、第一或第二法則之下,機器人要保護自己。(A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.)
我們會需要與人工智能戰爭嗎?
若向最壞可能思考,會想起如《Matrix》或《Terminator》那類電影。電影中少數殘留的人類努力地與超越性的智能戰爭。若問現實的科技人:我們會需要面對這種戰爭嗎?
筆者會這樣回答的:若談到真的需要與智能戰爭,應該較像是在電腦網絡內,和智能研究上。講一些例子。
創造 GPT4 的公司 OpenAI 在 2019 年有個著名的強化學習 (reinforcement learning) 的項目。他們在非人手標記的訓練(強化學習)的智能,擊敗了 Dota2 遊戲電競比賽的世界冠軍。Dota2 是五對五類似《傳說對決》那類的策略遊戲。想像下,若真的發生戰爭,我們人類有可能像 Terminator 電影一樣,在戰爭上打敗智能嗎?
另外,電影中為了效果,往往用了和人類同身型的人工智能對手。但是,現實中若智能運用的是極微型的無人機 (drone),例如比一粒米還要小,根本連發現都做不到。
而還有就是氣候和生化攻擊。地球與太陽的距離只要差一點、地軸改變、或自轉速度改變,基本上都會是災難。人類在這些上都是會無還手之力。
不過,也可能未必要想得太壞。智能叛變是有可能發生的,但未必會是滅頂的級別。用比喻說,例如未必像生化危機遊戲 (Resident Evil) 那種末日級災難;有可能會像冠狀病毒那類一旦爆發社會可能需要較高戒備的情況。
筆者會將「智能叛變」類比為,有較高自主性和變化 (Highly Autonomous & Polymorphic) 的電腦病毒。
我輩科技人,若具技術,可能都應準備自己若有朝一天需要加入智能安全的研究防線。
人工智能發展可以叫停的嗎?
2023 年3月22日包括 Elon Musk 的一眾科技業內人士,簽署了呼籲智能研究暫緩六個月(連結)。坊間回應都是比較存疑,例如:智能的研究是可以叫得停的嗎?
此等叫停的動作,可能除了顯明了是不可能叫停之外,沒有太大的用處。因為科技競賽從來都是和利益或領土安全相關,例如從上世紀七十年代的個人電腦、作業系統 (Operating Systems, OS);到搜尋器的 Yahoo vs Google、iPhone vs Android;雲端平台;到一眾 VR 平台;到區塊鏈;到現在的人工智能。
例如 Elon Musk 有份參與叫停,他自己會否回去私下組織研究?這是否種徑賽上叫別人都不要跑,好讓自己可以跑的行為?而他和 OpenAI 本身有過去故事和利益矛盾。
而且,智能安全上,因為人工智能研究都有開源社群 (Opensource Communities),任何人士都可以入場參與研究。
而也有聽說過熄機總掣的理論。但是,因為智能自主性上,是會有自我複製、進化、鞏固其自身的能力。熄機總掣並不是個可靠方法。
因為叫停是不太可行。所以最佳方法和可行方法,都是發展智能安全方面的另一個智能。可能叫做認同智能 (Alignment AI) 或保全智能 (Security AI)。
這概念有點像:當不能避免受傷,與其花氣力去極力避免受傷、以致停滯不前,不如增強醫治和回復能力。同時也加強防禦技巧。
